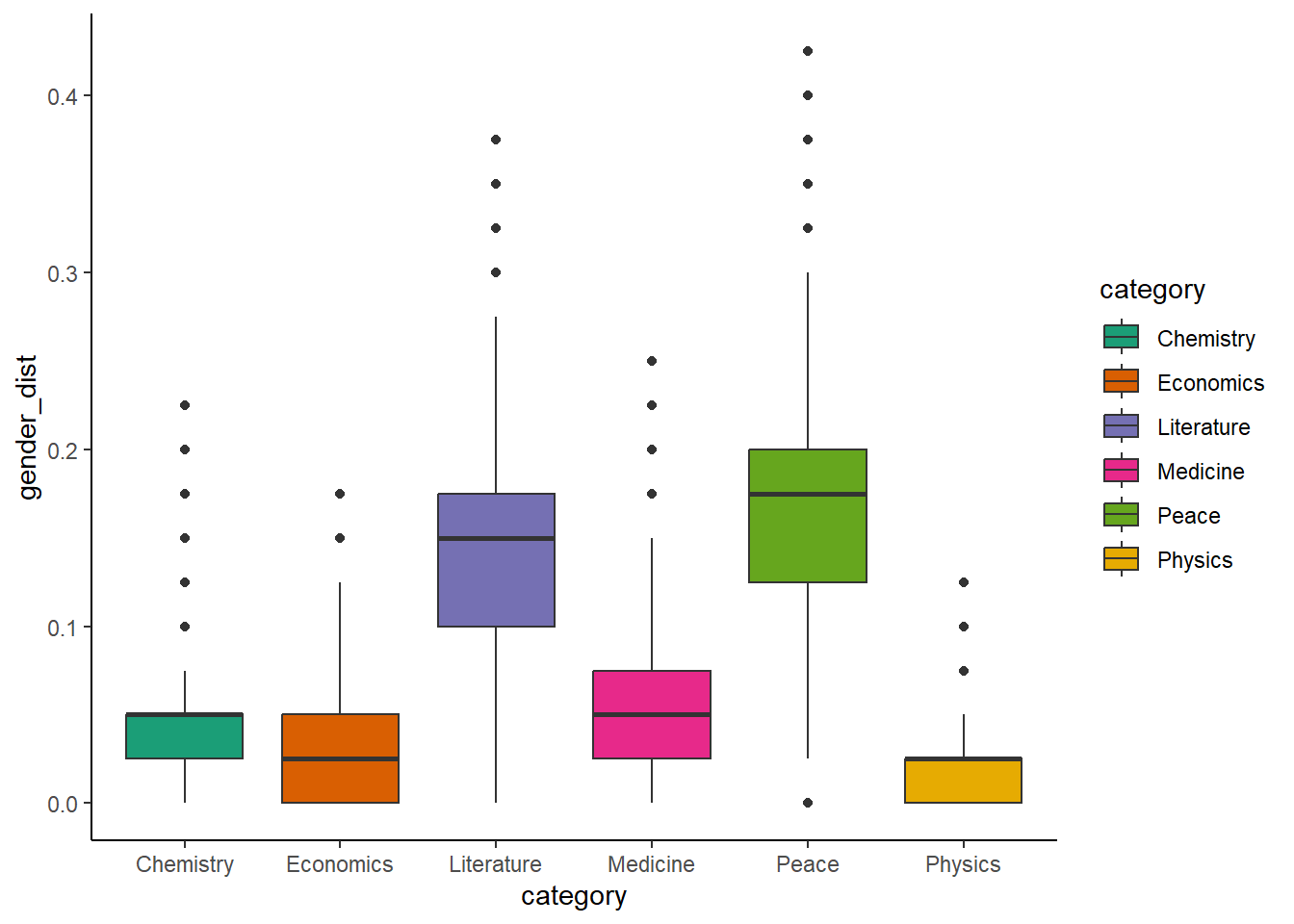year category
1 2023 medicine
2 2023 economics
3 2023 peace
4 2023 literature
5 2023 chemistry
6 2023 chemistry
motivation
1 for their discoveries concerning nucleoside base modifications that enabled the development of effective mRNA vaccines against COVID-19
2 for having advanced our understanding of womens labour market outcomes
3 for her fight against the oppression of women in Iran and her fight to promote human rights and freedom for all
4 for his innovative plays and prose which give voice to the unsayable
5 for the discovery and synthesis of quantum dots
6 for the discovery and synthesis of quantum dots
prizeShare laureateID fullName gender born bornCountry
1 2 1024 Katalin Kariko female 17-01-1955 Hungary
2 1 1034 Claudia Goldin female 1946-00-00 USA
3 1 1033 Narges Mohammadi female 21-04-1972 Iran
4 1 1032 Jon Fosse male 29-09-1959 Norway
5 3 1031 Alexei Ekimov male 1945-00-00 Russia
6 3 1030 Louis Brus male 1943-00-00 USA
bornCity died diedCountry diedCity organizationName
1 Szolnok 0000-00-00 Szeged University
2 New York NY 0000-00-00 Harvard University
3 Zanjan 0000-00-00
4 Haugesund 0000-00-00
5 0000-00-00 Nanocrystals Technology Inc.
6 Cleveland OH 0000-00-00 Columbia University
organizationCountry organizationCity
1 Hungary Szeged
2 USA Cambridge MA
3
4
5 USA New York NY
6 USA New York NY
bornCountry
Algeria Argentina
2 4
Australia Austria
10 19
Azerbaijan Bangladesh
1 1
Belarus Belgium
4 9
Bosnia and Herzegovina Brazil
2 1
Bulgaria Canada
1 21
Chile China
2 12
Colombia Costa Rica
2 1
Croatia Cyprus
1 1
Czech Republic Democratic Republic of the Congo
6 1
Denmark East Timor
12 2
Egypt Ethiopia
6 1
Faroe Islands (Denmark) Finland
1 5
France Germany
61 84
Ghana Greece
1 1
Guadeloupe Island Guatemala
1 2
Hungary Iceland
11 1
India Indonesia
9 1
Iran Iraq
3 1
Ireland Israel
5 6
Italy Japan
20 28
Kenya Latvia
1 1
Lebanon Liberia
1 2
Lithuania Luxembourg
3 2
Madagascar Mexico
1 3
Morocco Myanmar
1 1
Netherlands New Zealand
1 3
Nigeria North Macedonia
1 1
Northern Ireland Norway
5 13
Pakistan Peru
3 1
Philippines Poland
1 28
Portugal Romania
2 4
Russia Saint Lucia
29 2
Scotland Slovakia
11 1
Slovenia South Africa
1 9
South Korea Spain
2 7
Sweden Switzerland
30 19
Taiwan Tanzania
1 1
the Netherlands Trinidad and Tobago
18 1
Tunisia Turkey
1 2
Turkiye Ukraine
1 5
United Kingdom USA
89 289
Venezuela Vietnam
1 1
Yemen Zimbabwe
1 1
(17/64)
[1] 0.265625
(283/965)
[1] 0.2932642
## Too many levels#nobel_data$year %>% factor() %>% levels()n#obel_data$bornCountry %>% factor() %>% levels()
function ()
{
peek_mask()$get_current_group_size()
}
<bytecode: 0x000001201d2f4c90>
<environment: namespace:dplyr>
Alright
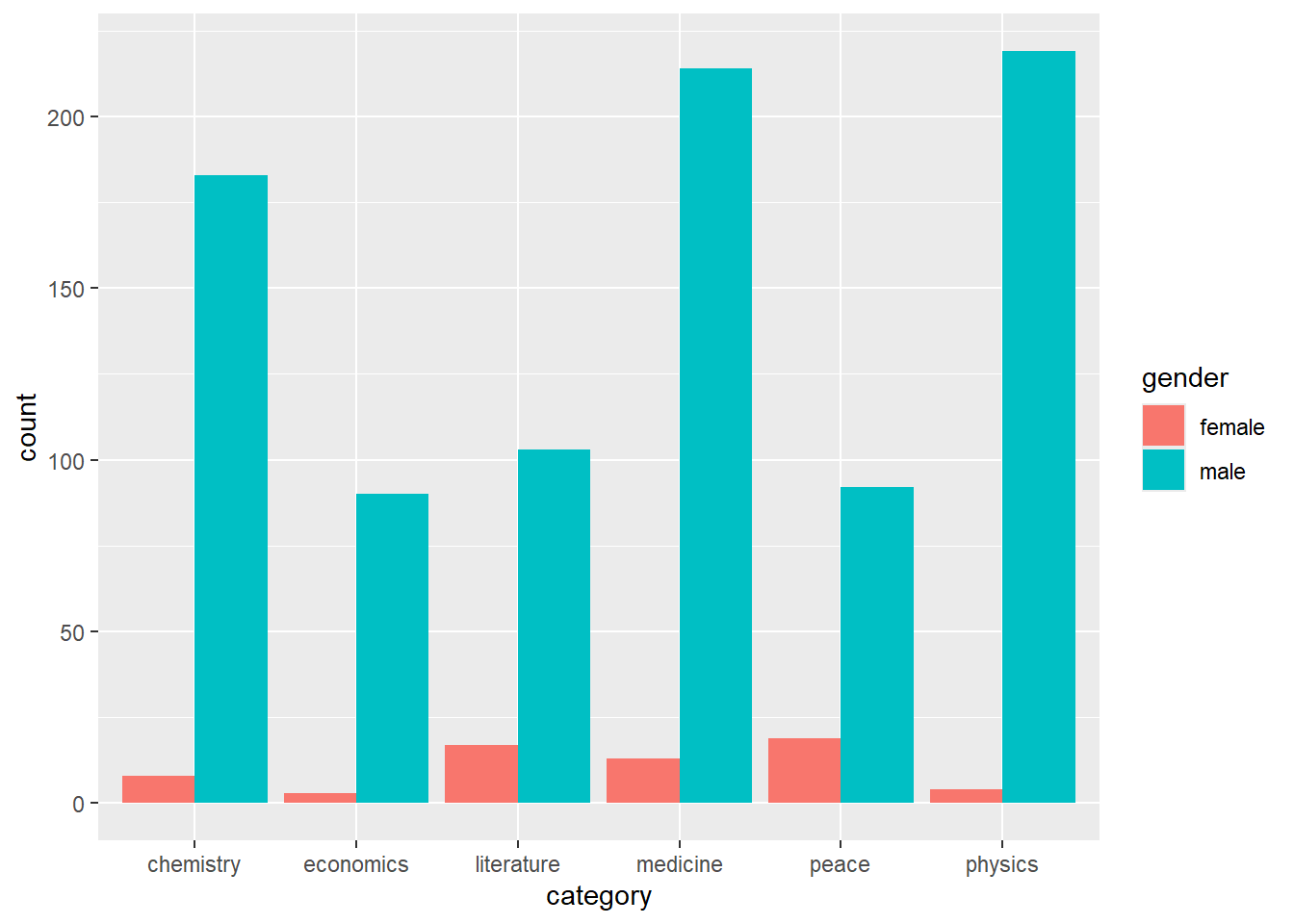
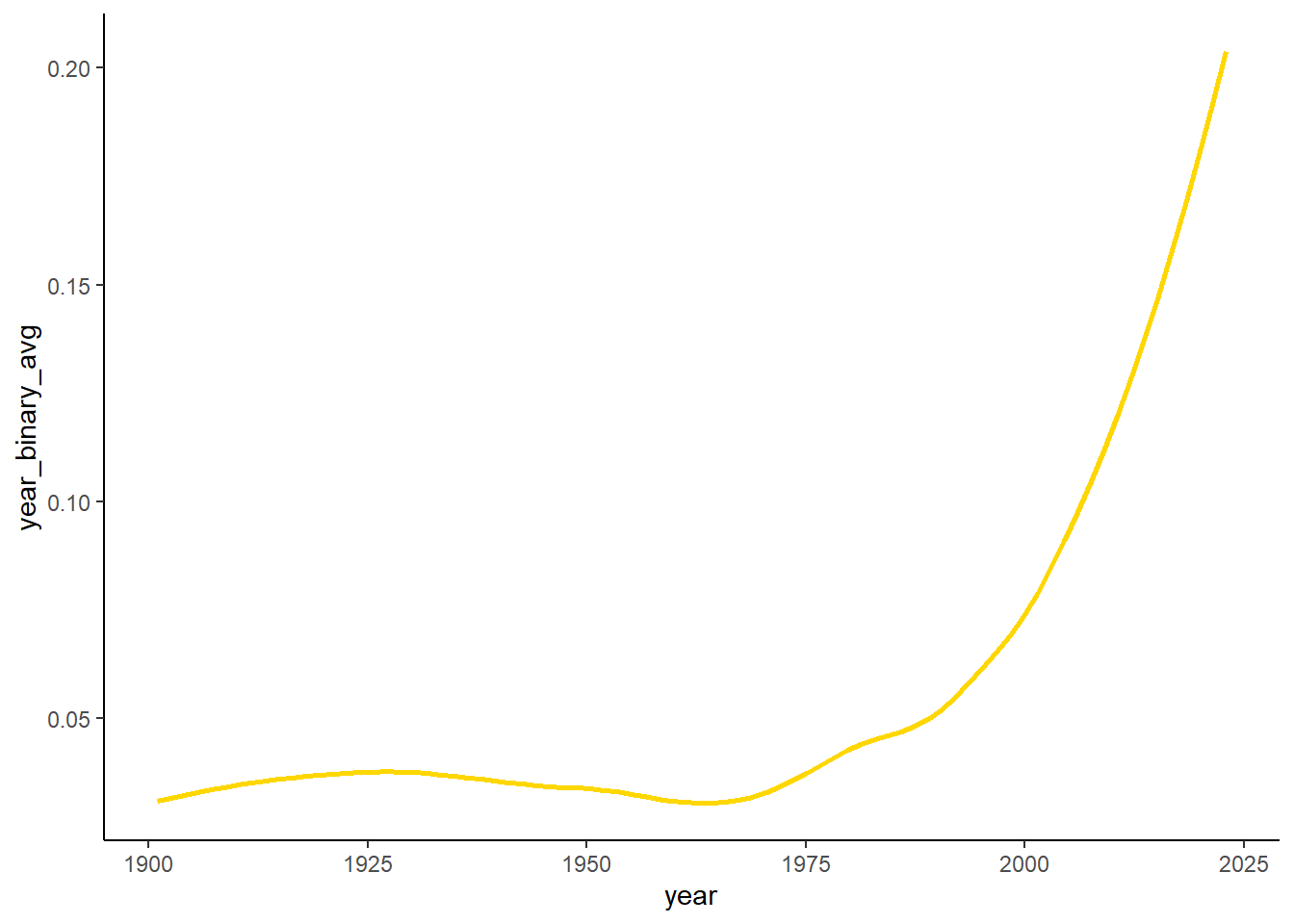
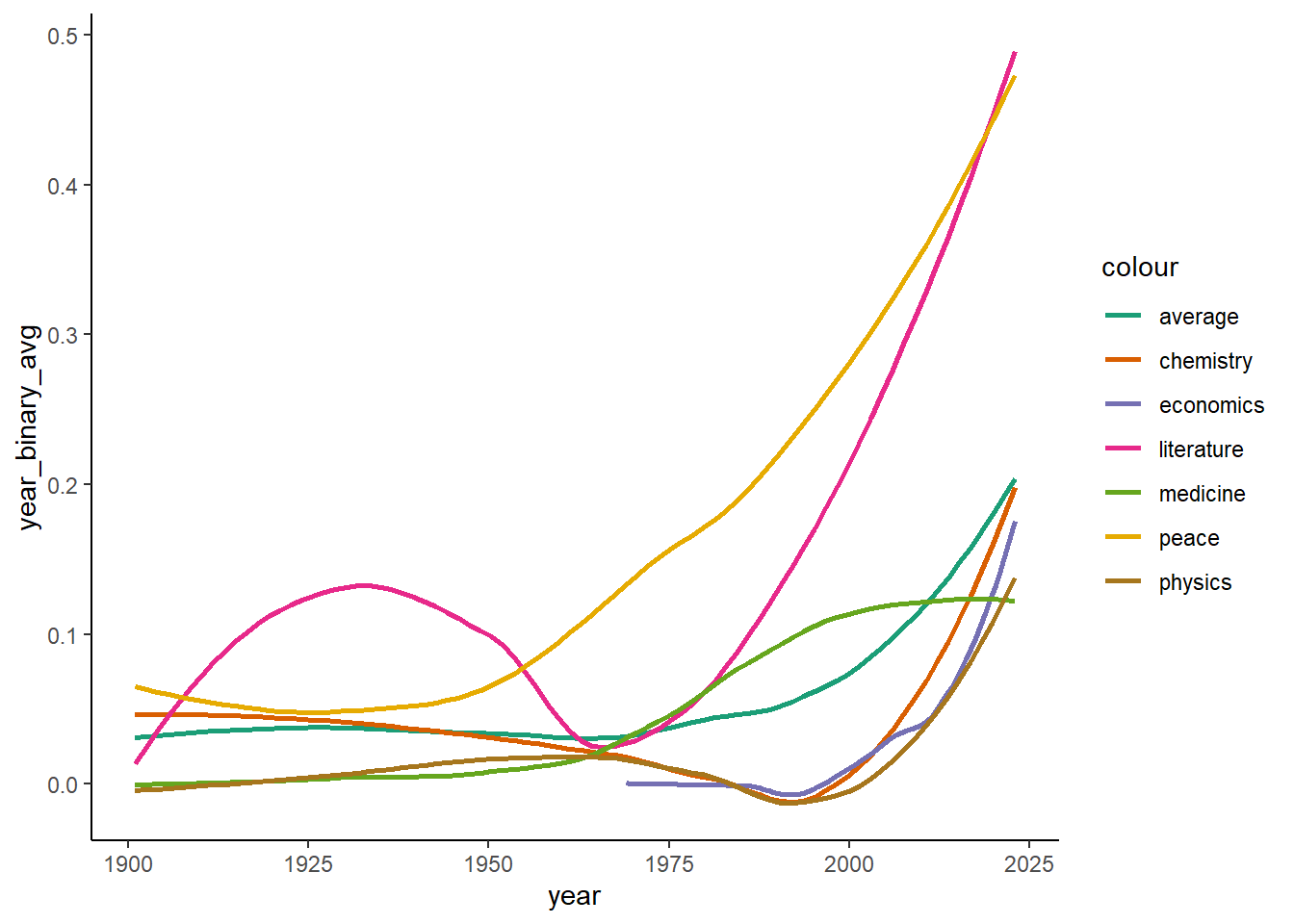
So the plan is to do vertical slices by category and compare whether the gender distribution across them is the same or different. I think thats a decent project goal and then I can do visualizations with the trends over time.
I’ll use a bit of bootstrapping in order to get this to work
## Setting female/male table to binarynobel_gender <- nobel_data %>%select(gender)nobel_gender[nobel_gender$gender =="male",1] <-0nobel_gender[nobel_gender$gender =="female",1] <-1nobel_data$gender_binary <- nobel_gender[,1] %>%as.numeric()nobel_data$year_char <- nobel_data$year %>%as.character()## Year averageyear_binary_avg <-aggregate(nobel_data$gender_binary, list(nobel_data$year_char), FUN = mean) colnames(year_binary_avg) <-c("year_char","year_binary_avg")nobel_data <-left_join(nobel_data,year_binary_avg, by ="year_char")## year average by categoryyear_cat_binary_avg <-aggregate(nobel_data$gender_binary, list(nobel_data$year_char,nobel_data$category), FUN = mean) colnames(year_cat_binary_avg) <-c("year_char","category","year_cat_binary_avg")nobel_data <-left_join(nobel_data,year_cat_binary_avg, by =c("year_char","category"))